") Toru Ishida,
Toru Ishida,
Department of Information Science.
Kyoto University.
Kyoto, 606, JAPAN.
ishida@kuis.kyoto- u.ac.jp

Sistemas de Producción Multiagente, Paralelos y Distribuidos
License: Proceedings of the First International Conference on Multiagent Systems. Copyright © 1995, AAAI (www.aaai.org). All rights reserved.Editor: First International Conference on Multiagent Systems. Copyright © 1995, AAAI (www.aaai.org).
DOI: https://doi.org/10.1007/3-540-58698-9
URL: https://www.aaai.org/Papers/ICMAS/1995/ICMAS95-056.pdf
Last revision: 2022/08/21
Citation: Ishida, T. (1994). Parallel, Distributed and Multiagent Production Systems (Vol. 878). Springer Berlin Heidelberg. https://doi.org/10.1007/3-540-58698-9
Control de citas: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27.
Investigación de fundamentos para la Inteligencia Artificial Distribuida
Resumen: Los sistemas de producción se han utilizado ampliamente como herramientas de creación de sistemas expertos y para la creación de modelos de descubrimiento-y-reacción en la ciencia cognitiva. Este documento pretende presentar los sistemas de producción paralelos/distribuidos/multiagente, y revelar sus posibilidades como elementos fundamentales de investigación en inteligencia artificial distribuida: siendo un sistema de producción paralelo similar a una arquitectura de agentes reactivos y, siendo un sistema de producción distribuido como una organización de agentes adaptativos. Se concluye con un sistema de producción multiagente como pieza de aprendizaje organizacional. Los sistemas de producción ya han sido equipados con una sintaxis/semántica clara y con algoritmos de coincidencia de patrones eficientes. Sus funciones se pueden fortalecer aún más con algoritmos recientes, como la búsqueda en tiempo real y el aprendizaje por refuerzo.
Palabras clave: sistemas de producción multiagente; herramientas de construcción de sistemas expertos, sistema de producción paralelo síncrono; sistemas de producción paralelos asíncronos
1. Introducción
Los sistemas de producción han sido estudiados como modelo cognitivo para humanos o como modelo para agentes inteligentes. Dado que la relación entrada-salida en cada regla está claramente descrita, los sistemas de producción atraen a personas que necesitan un lenguaje para describir procesos de toma de decisiones no deterministas. Una vez que Forgy implementó un algoritmo de coincidencia de patrones de alta velocidad [Forgy, 1982]5, los sistemas de producción se convirtieron en la herramienta de creación de sistemas expertos más popular.
Con el éxito de los sistemas expertos (p.e., XCON), los investigadores comenzaron a trabajar en el procesamiento paralelo para mejorar el rendimiento de los sistemas de producción. Debido a que el 90% del tiempo de procesamiento se consume en la comparación de patrones, primero se estudió la comparación en paralelo. El autor, sin embargo, está más interesado en ejecutar reglas al mismo tiempo. Los sistemas de producción concurrente se pueden clasificar en tres categorías:
-
Sistemas de producción paralelos sincrónicos o de disparo de reglas en paralelo [Ishida y Stolfo, 1985; Ishida, 1991]11,14, donde las reglas se activan en paralelo para reducir el número total de ciclos de producción secuenciales, mientras que las activaciones de reglas se sincronizan globalmente en cada ciclo de producción.
-
Sistemas de producción paralelos asíncronos o sistemas de producción distribuidos [Ishida et al, 1990; 1992; Gasser e Ishida, 1991]13,19,6, donde las reglas se distribuyen entre varios procesos y se disparan en paralelo sin sincronización global.
-
Sistemas de producción multiagente [lshida, 1992b]18, donde múltiples programas de sistemas de producción compiten o cooperan para resolver uno o varios problemas.
Dado que los sistemas de producción se han utilizado para describir el conocimiento estático, las personas sienten que los sistemas de producción no son adecuados para manejar dinámicamente los problemas del mundo real. El objetivo de este trabajo es mostrar las posibilidades de los sistemas de producción concurrente como base para la investigación de la inteligencia artificial distribuida.
Nuestra intuición es que una colección de sistemas de producción podría ser un modelo de una sociedad humana dinámica, ya que cada sistema de producción puede representar el ciclo de reconocimiento y reacción de un ser humano individual. El resto de este documento revela sus habilidades potenciales para resolver problemas dinámicos del mundo real: un sistema de producción paralelo al igual que la arquitectura reactiva de agentes, un sistema de producción distribuido del mismo modo que una organización de agentes adaptativos y un sistema de producción de múltiples agentes para emular el aprendizaje organizacional.
2. Una revisión de los sistemas de producción
Probablemente fue desafortunado que en los primeros sistemas de producción exitosos se encontrase el sistema experto XCON, que puede crear una configuración óptima de sistemas informáticos bastante complejos [Soloway et al., 1987]25. El éxito llevó a la expectativa irrazonable de que “los sistemas de producción pueden resolver problemas complejos sin describir los procedimientos”. Sin embargo, esto era engañoso. A diferencia de Prolog, los sistemas de producción no tienen un mecanismo de seguimiento. Un sistema de producción se refiere a una memoria de trabajo que representa un mundo real, encuentra reglas que se pueden activar y selecciona una regla para cambiar la memoria de trabajo. Cuando se necesita retroceder, se deben ejecutar acciones inversas. Si no se dispone de una acción inversa, no hay forma de recuperar la situación. Recuerde el famoso ejemplo del “mono y los plátanos”. Este ejemplo muestra lo difícil que es para un sistema de producción crear una secuencia de acciones (e.g., planes). Los sistemas de producción son inherentemente adecuados para ejecutar reglas de tipo estímulo-respuesta, pero no son lo suficientemente poderosos para producir procedimientos complejos.
Figure 1. Controlando el disparo de la regla
Rule: (P ruleA (class1)
-->
(make class2)
(remove clasa1))
(P ruleB (class1)
:
Plan-1: (dotimes (i 100) (? ruleA))
Plan-2: (loop (select ((? ruleA))
((? ruleB))
((? ruleC))
(otherwise (return))))
Entonces, ¿Cómo limitar el disparo de reglas generado por la propia regla? Una forma es introducir la descripción del control procedimental [Ishida et al., 1991; 1995].16–20. La idea clave es ver los sistemas de producción como una colección de procesos de reglas independientes, cada uno de los cuales monitorea una memoria de trabajo y realiza acciones cuando sus condiciones son satisfechas por la memoria de trabajo. Las macros de control de procedimientos, que se basan en el CSP de Hoare [Hoare, 1978]8, pueden introducirse para establecer vínculos de comunicación entre los procesos de control de meta-nivel y la colección de procesos de reglas.
La figura 1 representa un ejemplo de codificación. Dado que las reglas pueden verse como procesos independientes, la campo comodín “?” que se basa en el comando de entrada CSP, se utiliza para invocar a una sola regla. Esta macro ejecuta la regla especificada, cuando se cumplen las condiciones de la regla. De lo contrario, la macro “?” supervisa la memoria de trabajo y espera los cambios de datos hasta que se cumplan las condiciones de la regla. Plan-1 que se muestra en la Figura 1 está escrito usando la macro ? y la macro dotimes de Lisp.
El intérprete del sistema de producción prueba los lados izquierdos de múltiples reglas simultáneamente y selecciona una regla ejecutable a través de la resolución de conflictos. Para ver los planes de control como una extensión natural de los intérpretes de sistemas de producción convencionales, se crea la macro de selección de reglas (select-macro), que está influenciada por el comando protegido CSP y el comando alternativo. El intérprete de tres reglas se puede expresar como Plan~2 en la Figura 1 usando select-macro. Este plan de control ejecuta repetidamente las tres reglas hasta que no se puede activar ninguna regla. Dado que las macros de control pueden aparecer en cualquier lugar de los programas Lisp, los intérpretes de sistemas de producción convencionales pueden ampliarse fácilmente y pueden invocarse desde cualquier lugar de los planes de control.
Hay otra forma de restringir los disparos de reglas: introducir un mecanismo de aprendizaje en los sistemas de producción. Holland propuso un mecanismo de aprendizaje por refuerzo llamado becket brigade [Holland, 1986]9, que distribuye el premio por el éxito de activación, no solo a la última regla sino también a las reglas ejecutadas antes. Refuerza la secuencia de reglas que conduce al éxito. Sin embargo, desde el punto de vista de la resolución de problemas, el trabajo no proporciona ningún resultado concreto: no sabemos qué clase de problemas pueden resolverse mediante este mecanismo. Q-learning [Watkins, 1989]26 es similar, pero puede garantizar la convergencia a la mejor política que maximiza las recompensas esperadas. Búsqueda en tiempo real [Koff, 1990; Ishida y Korf 1991; Ishida 1992a]21,15,17 también es capaz de aprender el mejor plan resolviendo repetidamente el problema dado. La relación entre Q-learning y la búsqueda en tiempo real fue aclarada por [Barto et al., 1993]1. Sorprendentemente, a pesar de que los antecedentes de estos investigadores son totalmente diferentes, ambos algoritmos se basan en el mismo mecanismo, programación dinámica y resuelven problemas de formas ligeramente diferentes.
Por ejemplo, supongamos que tenemos un robot en un gran laberinto. El robot puede moverse hacia la derecha, hacia la izquierda, hacia adelante y hacia atrás. Si el robot puede identificar su estado (p. ej., eje zy), estos algoritmos aprenden gradualmente las secuencias de acción óptimas para escapar del laberinto. Q-learning es aplicable cuando se desconocen las probabilidades de las transiciones de estado. De lo contrario, la búsqueda en tiempo real es más eficiente. Los sistemas de producción pueden proporcionar una descripción de nivel lógico de los estados de estos algoritmos de aprendizaje.
2.1. Sistemas de Producción en Paralelo para Comportamiento Reactivo
Un sistema de producción puede verse como un conjunto de reglas, cada una de las cuales monitorea la memoria de trabajo. Una vez que se cumple la condición previa, cada regla intenta activarse a sí misma. Sin embargo, en los sistemas de producción secuencial, el mecanismo de resolución de conflictos selecciona solo una de las reglas, de modo que las reglas se disparan secuencialmente. Por otro lado, en los sistemas de producción paralelos, ejecutamos simultáneamente tantas reglas como sea posible [Ishida y Stolfo, 1985]. El problema fundamental en la activación de reglas en paralelo es cómo garantizar la serialización de las activaciones de reglas. Se introduce el análisis de interferencias para detectar casos en los que un resultado de disparo paralelo difiere del resultado de disparos secuenciales de las mismas reglas en cualquier orden.
Para analizar la interferencia entre reglas múltiples en instanciaciones de reglas de producción, se introduce un gráfico de dependencia de datos de los sistemas de producción, que se construye a partir de las siguientes primitivas: un nodo de producción (un nodo P que se muestra como un círculo en las figuras), que representa un conjunto de instanciaciones, un nodo de memoria de trabajo (un nodo W mostrado como un cuadrado), que representa un conjunto de elementos de memoria de trabajo, un hecho externo dirigido desde un nodo-P a un nodo-W, que representa el hecho que un P-nodo modifica un W-nodo, y un hecho externo dirigido de un W-nodo a un P-nodo, el cual representa el hecho de que un P-nodo se refiere a un W-nodo.
Por ejemplo, en la Figura 2(a), suponga que inicialmente existen dos elementos de memoria de trabajo: (clase1) y (clase2). Si las reglas se activan secuencialmente, queda (clase1) cuando la reglaA se ejecuta por primera vez, o (clase2) …
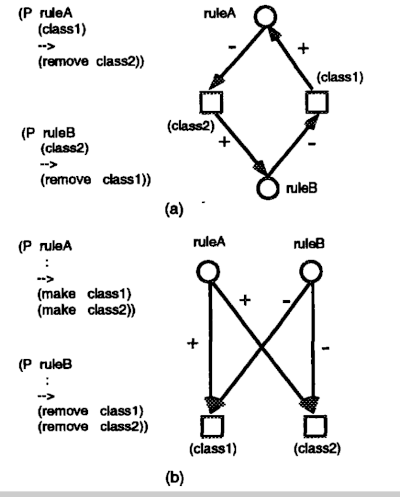
Figura 2. Interferencias entre Reglas
cuando ruleB se ejecuta por primera vez. Sin embargo, si las dos reglas se activan en paralelo, no queda ningún elemento de memoria de trabajo. La figura 2(b) considera el caso en el que no hay ningún elemento de memoria de trabajo antes de la ejecución. Si las reglas se activan secuencialmente, no queda ningún elemento de la memoria de trabajo cuando se ejecuta la reglaA por primera vez, o quedan dos elementos de la memoria de trabajo, (clase 1) y (clase 2), cuando la regla B se ejecuta primero. Sin embargo, si las reglas se disparan en paralelo, hay cuatro posibilidades, es decir, (clase1) y (clase2) permanecen, (clase1) permanece, (class2) permanece o no queda ningún elemento de la memoria de trabajo.
Sobre la base de un gráfico de dependencia de datos de los sistemas de producción, se proporcionan técnicas generales aplicables a los análisis de compilación y tiempo de ejecución. A continuación, se proponen dos algoritmos para realizar disparos de reglas paralelas en sistemas reales de múltiples procesadores: Se proporciona un algoritmo de selección eficiente para seleccionar múltiples reglas que se dispararán en paralelo mediante la combinación de técnicas de análisis de interferencia en tiempo de ejecución y compilación. El algoritmo de composición divide el programa del sistema de producción dado y aplica las particiones a procesos paralelos. También se proporciona un lenguaje de programación paralelo para permitir a los programadores hacer pleno uso del paralelismo potencial sin tener en cuenta el mecanismo paralelo interno.
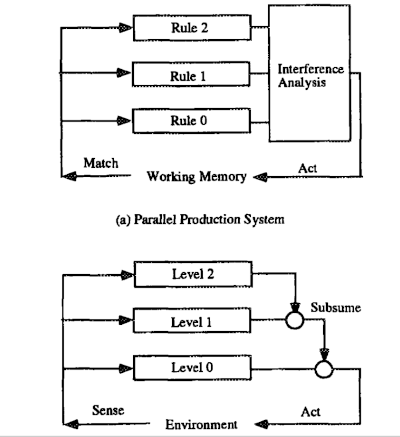
Figura 3. Arquitecturas Reactivas
Comparemos las arquitecturas de los sistemas de producción en paralelo y una arquitectura de subsunción [Brooks, 1986]2. La Figura 3(a) ilustra los sistemas de producción en paralelo, mientras que la Figura 3(b) representa la arquitectura de subsunción considerada. La diferencia entre ellos es el papel de los mediadores. En los sistemas de producción en paralelo, el mediador centralizado detecta y evita las interferencias entre reglas. En la arquitectura de subsunción, el mediador distribuido inhibe las actividades de nivel inferior. Dado que el mediador podría distribuirse en sistemas de producción paralelos [Ishida, 1991]14, no existe una diferencia importante entre ellos. Al generalizar el proceso del mediador, un sistema de producción paralelo puede representar sistemas basados en una arquitectura de subsunción.
2.2. Sistemas de Producción Distribuidos para la Adaptación Organizacional
Para la ejecución asíncrona de sistemas de producción: la activación de reglas paralelas, con control global, se extiende para la activación de reglas distribuidas; los problemas son resueltos por una sociedad de agentes del sistema de producción utilizando control distribuido. Luego se introduce el diseño propio de la organización en los sistemas de producción distribuidos para proporcionar una asignación de trabajo adaptativo. En nuestro modelo, las solicitudes de resolución de problemas emitidas desde el entorno llegan a la organización de forma continua y con tasas variables. Para responder, la organización debe proporcionar resultados significativos dentro de los límites de tiempo especificados. Se han introducido recientemente dos primitivas de reorganización, composición y descomposición. Estas primitivas cambian el número de sistemas de producción y la distribución de reglas en una organización.
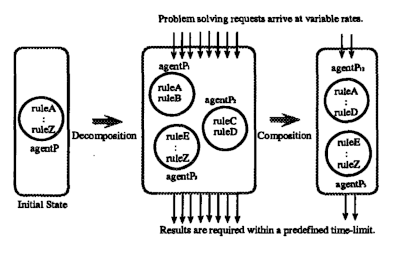
Figura 4. Adaptación de la Organización
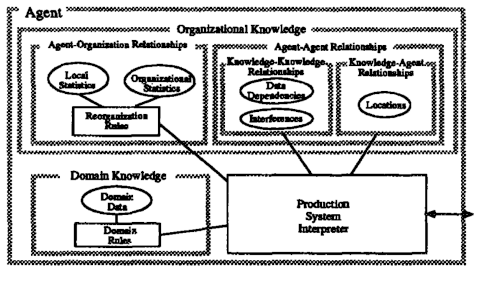
Figura 5. Agente del sistema de producción
El autodiseño de la organización es útil cuando existen restricciones en tiempo real y el sistema de producción tiene que adaptarse a requisitos ambientales cambiantes. Cuando están sobrecargados, los agentes individuales se descomponen para aumentar el paralelismo, y cuando la carga se aligera, los agentes se combinan entre sí para liberar recursos de hardware adicionales. La Figura 4 muestra el comportamiento de la adaptación organizacional.
Ninguna organización por sí sola puede manejar adecuadamente todos los problemas y condiciones ambientales. Por ejemplo, supongamos que hay tres agentes en una organización, cada uno de los cuales activa una regla de producción para resolver cada solicitud de problema, los tres agentes trabajan de forma canalizada (porque sus reglas son secuencialmente dependientes) y el retraso en la comunicación entre los agentes es igual a un ciclo de producción. Por lo tanto, el tiempo de ciclo de rendimiento total para satisfacer una sola solicitud es 5. En este caso, sin embargo, una organización de un solo agente se desempeñaría mejor debido a la reducción de la sobrecarga de comunicación; tomaría solo 3 ciclos para satisfacer una sola solicitud. Por otro lado, si hubiera diez solicitudes de resolución de problemas, el tiempo de respuesta de la última solicitud sería de 14 ciclos en la organización de tres agentes, mientras que sería de 30 en el caso de un solo agente. Un agente del sistema de producción es un sistema de producción capaz de interactuar con otros agentes. Como se ilustra en la Figura 5, el agente del sistema de producción consta de un intérprete del sistema de producción y conocimiento del dominio, que incluye reglas de dominio y datos de dominio. Tenga en cuenta que cada agente contiene una parte del conocimiento del dominio. Para llevar a cabo la resolución de problemas de dominio de forma distribuida, los agentes necesitan conocimiento organizativo, que representa tanto las interacciones necesarias entre los agentes como su organización. El conocimiento organizacional se obtiene inicialmente analizando el conocimiento del dominio en el momento de la compilación, y se obtiene dinámicamente durante el proceso de autodiseño de la organización.
Dado que los agentes realizan la reorganización de forma asincrónica, el conocimiento organizativo puede ser temporalmente incoherente entre los agentes. El conocimiento organizacional se clasifica además en varias categorías. Las relaciones agente-agente pueden verse como la agregación de dos tipos más primitivos de relaciones: relaciones conocimiento-conocimiento, que representan interacciones dentro del dominio del conocimiento, y relaciones conocimiento-agente que representan cómo se distribuye el conocimiento del dominio entre los agentes. Las relaciones conocimiento-conocimiento consisten en dependencias de datos e interferencias entre reglas de dominio. Un agente que tiene tal relación de conocimiento-conocimiento con un agente en particular se denomina vecino de ese agente. La figura 6 ilustra las relaciones agente-agente.
Para una reorganización apropiada, el conocimiento organizacional incluye las relaciones agente-organización, que representan cómo las decisiones locales de los agentes afectan el comportamiento organizacional. En nuestro caso, las relaciones agente-organización consisten en estadísticas locales, estadísticas organizacionales y reglas de reorganización. Dado que las reglas de reorganización también son reglas de producción, el diseño propio de la organización y la resolución de problemas de dominio se intercalan arbitrariamente. Dado que varios agentes activan reglas y realizan reorganizaciones de forma asincrónica, es difícil conocer el estado exacto de toda la organización. Bajo la política de obtener mejores decisiones con la máxima localidad, primero se introducen estadísticas locales y organizacionales, que se pueden obtener fácilmente, y luego se proporcionan reglas de reorganización que usan esas estadísticas para seleccionar una primitiva de reorganización apropiada cuando sea necesario.
La figura 7 muestra los resultados de la evaluación. En esta figura, se ignoran los gastos generados por comunicación y reorganización. El gráfico de líneas indica tiempos de respuesta normalizados por ciclos de producción. El gráfico de pasos representa el número de agentes en la organización. El límite de tiempo se establece en 20 ciclos de producción, mientras que el período de medición se establece en 10 ciclos de producción. En la Figura 7, las solicitudes de resolución de problemas llegan a intervalos constantes. Alrededor del tiempo 100, el tiempo de respuesta supera con creces el límite de tiempo. Así la organización comienza a descomponerse. Alrededor del tiempo 200, el número de agentes ha aumentado a 26, el tiempo de respuesta cae por debajo del límite de tiempo y la organización comienza la composición. Después de fluctuar ligeramente, la organización finalmente alcanza un estado estable con el número de agentes estableciéndose en 6. Dado que la composición y la descomposición se intercalaron, las proporciones de disparo de los agentes resultantes son casi iguales. Este gráfico muestra que la sociedad de agentes se ha adaptado gradualmente a la situación a través de reorganizaciones repetidas.
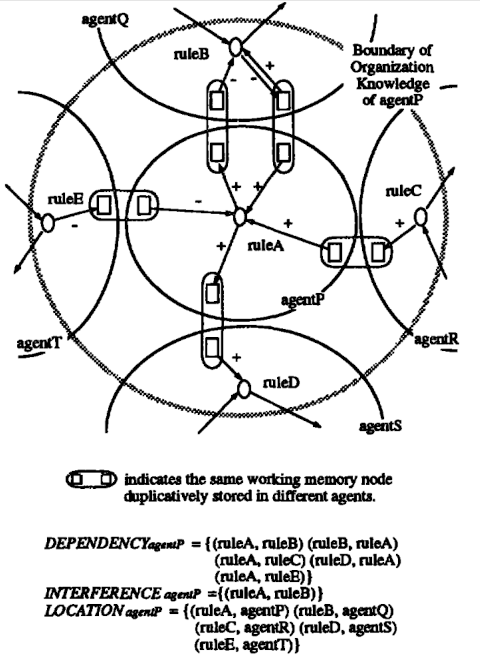
Figura 6. Conocimiento Organizacional
2.3 Sistemas de producción multiagente para el aprendizaje organizacional
Los sistemas de producción multiagente son múltiples sistemas de producción independientes que interactúan y, por lo tanto, son diferentes de los sistemas de producción paralelos o distribuidos. Por lo tanto, se introdujo un modelo de transacción para lograr la activación arbitraria de reglas intercaladas de múltiples agentes del sistema de producción [Ishida, 1992b]18. Sin embargo, como resultado de permitir activaciones de reglas intercaladas, garantizar la serialización ya no es suficiente para garantizar la consistencia de la información de la memoria de trabajo compartida.
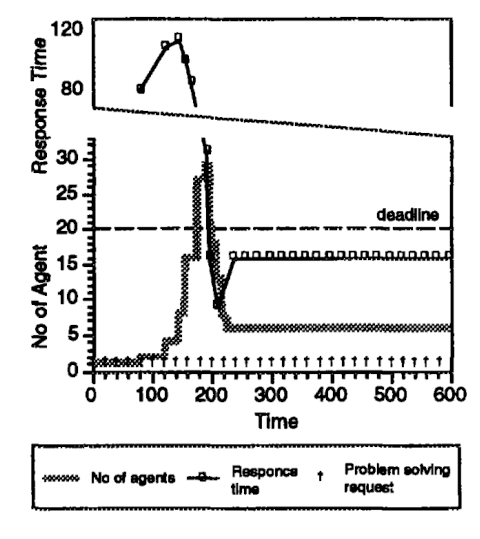
Figura 7. Evaluación del desempeño
Un modelo de dependencia lógica y sus mecanismos de mantenimiento como DTMS (Distributed Truth Maintenance System) [Huhns and Bridgeland, 1991]10 o algoritmos de satisfacción de restricciones distribuidos [Yokoo et al., 1992]27 se han introducido para superar este problema.
El tema del control se vuelve cada vez más serio en los sistemas de producción multiagente. Debido a que varios eventos ocurren de manera asíncrona en una red de múltiples agentes, los agentes deben controlar de manera cooperativa sus procesos de ejecución de reglas. Luego, esto requirió de una arquitectura de control de meta-nivel para priorizar la activación de reglas, para centrar la atención de múltiples agentes en las tareas más urgentes. Esta arquitectura se ha aplicado para construir un sistema multiagente denominado CoCo [Ishida, 1989]12, que actualmente realiza operaciones cooperativas como el control de redes telefónicas públicas conmutadas.
A partir de la investigación anterior, nos dimos cuenta de la importancia de describir los protocolos entre agentes. Los protocolos de telecomunicaciones convencionales han sido estudiados para garantizar el rendimiento y la transparencia de las comunicaciones de datos. Los protocolos desarrollados hasta ahora son principalmente para capas inferiores (inferiores a la capa de transporte) y, por lo tanto, no se les ha pedido a los usuarios que diseñen y verifiquen los protocolos que usaron. Sin embargo, lo que necesitamos ahora es un protocolo entre agentes para integrar varios programas de aplicación diseñados de forma independiente por diferentes usuarios. Kuwabara ha estado desarrollando un lenguaje llamado AgenTalk para describir protocolos de coordinación para sistemas de múltiples agentes [Kuwabara, 1995; Kuwabara et al., 1995]23,22.
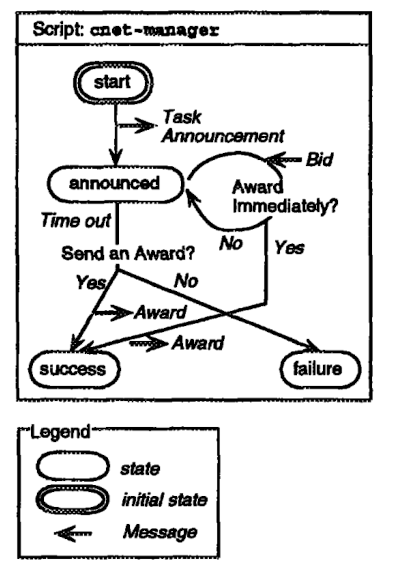
Figura 8. AgenTalk [Kuwabara et al., 1995]22
En AgenTalk, los protocolos entre agentes están definidos por autómatas que son máquinas de estado (de estado finito). Usando AgenTalk, Kuwabara describe el comportamiento del gerente siguiendo el protocolo contract-net. La asignación de tareas en el protocolo contract-net se realiza de la siguiente manera: en primer lugar, un administrador con una tarea para ejecutar transmite un mensaje de anuncio de tarea (Task Announcement). Un contratista que está dispuesto a ejecutar la tarea anunciada envía un Mensaje de oferta (Bid Message). El gerente selecciona un contratista al que se le asignará la tarea y le envía un Mensaje de adjudicación (Award Message_). La secuencia de comandos del administrador cnet-manager se muestra en la Figura 8. Se supone que la secuencia de comandos del cnet manager se invoca cuando se genera la tarea que se asignará.
Aunque el enfoque de autómatas de estado finito para describir protocolos es común en una comunidad informática distribuida, la gente de inteligencia artificial en tiempo real señaló la similitud de AgenTalk y PRS (Sistema de razonamiento procedimental) [Georgeff y Lansky, 1987]*7 *. Desde nuestro punto de vista, ambos sistemas se basan en el mismo marco de transición de estado: PRS describe la interacción entre un agente y un entorno, mientras que AgenTalk describe el protocolo entre múltiples agentes.
AgenTalk está diseñado para describir varios protocolos entre agentes. La característica clave de AgenTalk es el mecanismo de herencia de la descripción del protocolo. Usando AgenTalk, hemos descrito el protocolo de negociación de múltiples etapas [Conry et al., 1991]4 como una extensión del protocolo de red de contrato contract-net [Smith, 1980]24. Se espera que muchos protocolos de coordinación específicos de aplicaciones aparezcan pronto a medida que se construyan los agentes de software. AgenTalk está diseñado para permitir que varios protocolos se definan de forma incremental y se personalicen fácilmente para los dominios de aplicación mediante la incorporación de un mecanismo de herencia. Sin embargo, introducir mecanismos de herencia en la descripción del protocolo genera nuevos problemas técnicos: por ejemplo, cómo verificar el protocolo personalizado, cuando se ha verificado el protocolo original.
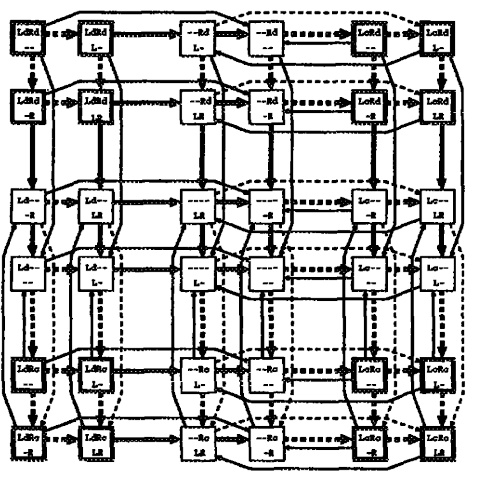
Figura 9. Los posibles estados en la cena de los filósofos
Un enfoque más interesante es introducir técnicas de aprendizaje automático en los protocolos entre agentes. Algunas clases de algoritmos distribuidos se pueden representar mediante un diagrama de transición de estado. Comencemos con los famosos “filósofos en la cena”, basados en el algoritmo de Chandy y Misra [Chandy y Misra, 1988]3. La figura 9 ilustra el diagrama de transición de estado de un filósofo cenando. Cada casilla representa el estado de un filósofo. La línea superior indica si un filósofo posee bifurcaciones L (izquierda) y R (derecha), y si cada bifurcación es e (limpia) o d (sucia). La línea inferior indica si un filósofo recibe una solicitud de los vecinos L (izquierda) y R (derecha). Hay dos tipos de transiciones de estado: activa y pasiva. La primera es desencadenada por el propio filósofo. Sin embargo, este última es desencadenada por filósofos vecinos y, por lo tanto, las probabilidades de las transiciones de estado no se conocen al principio. En la Figura 9, los bordes sólidos representan transiciones activas y los bordes discontinuos representan transiciones pasivas. Las transiciones de estado permitidas por el algoritmo de Chandy y Misra están representadas por bordes gruesos. El desafío aquí es aprender las transiciones de estado representadas por los bordes gruesos a través de la interacción repetida con otros filósofos. Los algoritmos de aprendizaje por refuerzo como Q-learning pueden ser la base para resolver este problema.
Conclusión
Aunque los sistemas de producción concurrente se investigaron por primera vez para mejorar el rendimiento, pueden proporcionar una base de investigación fructífera para la inteligencia artificial distribuida. Un sistema de producción en paralelo puede describir arquitecturas reactivas mediante la generalización de su mediador. Un sistema de producción distribuida puede ser un banco de pruebas de investigación para una organización de agentes adaptativos. Un sistema de producción multiagente también proporciona una base clara para el aprendizaje organizacional. Los protocolos se representan primero mediante un conjunto de reglas reactivas y luego se adaptan gradualmente a sus entornos de ejecución. La introducción del aprendizaje de protocolos nos ofrece una vía hacia sistemas distribuidos flexibles.
Agradecimientos
El autor agradece a L. Gasser, K. Kuwabara, M. Yokoo and T. Sugimoto su contribución a este documento de trabajo.
Bibliografía
-
[Barto et al., 1993] A. G. Barto, S. J. Bradtke and S. P. Singh, “Learning to Act Using Real-Time Dy namic Programming,” UMASS Tech Rep., 1993. ↩ ↩2
-
[Brooks, 1986] R. A. Brooks, “A Robust Layered Con trol System for a Mobile Robot,” IEEE Trans. RA, Vol. 2, No. 1, 1986. ↩ ↩2
-
[Chandy and Misra, 1988] K. M. Chandy and J. Misra, Parallel Program Design, Addison-Wesley, 1988. ↩ ↩2
-
[Conry at ai., 1991] S. E. Conry, K. Kuwabara, V. R. Lesser and R. A. Meyer, “Multistage Negotiation for Distributed Constraint Satisfaction,” IEEE Trans. SMC, Vol. 21, No. 6, pp. 1462-1477, 1991. ↩ ↩2
-
[Forgy, 1982] C. L. Forgy, “RETE: A Fast Algorithm for the Many Pattern / Many Object Pattern Match Problem,” Artificial Intelligence, Voi. 19, pp. 17-37, 1982. ↩ ↩2
-
[Gasser and Ishida, 1991] L. Gasser and T. Ishida, “A Dynamic Organizational Architecture for Adaptive Problem Solving,” AAAI-91, pp. 185-190, 1991. ↩ ↩2
-
[Georgeff and Lansky, 1987] M. P. Georgeff and A. L. Lansky, “Reactive Reasoning and Planning,” AAAI 87, pp. 677-682, 1987. ↩ ↩2
-
[Hoare, 1978] C. A. R. Hoare, “Communicating Se quential Processes,” CACM, Vol. 21, No. 8, pp. 666-677, 1978. ↩ ↩2
-
[Holland, 1986] J. H. Holland, “Escaping Brittleness: The Possibilities of General-Purpose Learning Al gorithm Applied to Parallel Rule-Bases Systems,” Machine Learning, Vol. 2, pp. 593-623, 1986. ↩ ↩2
-
[Huhns and Bridgeland, 1991] M. N. Huhns and D. M. Bridgeland, “Multiagent Truth Maintenance,” IEEE Trans. SMC, Vol. 21, No. 6, pp. 1437-1445, 1991. ↩ ↩2
-
[Ishida and Stolfo, 1985] T. lshida and S. J. Stolfo, “Towards Parallel Execution of Rules in Production System Programs,” ICPP-85, pp. 568-575, 1985. ↩ ↩2
-
[Ishida, 1989] T. Ishida, “CoCo: A Multi-Agent System for Concurrent and Cooperative Operation Tasks,” International Workshop on Distributed Ar tificial Intelligence , pp. 197-213, 1989. ↩ ↩2
-
[lshida et al., 1990] T. Ishida, M. Yokoo and L. Gasser, “An organizational Approach to Adaptive Production Systems,” AAAI-90, pp. 52-58, 1990. ↩ ↩2
-
[Ishida, 1991] T. Ishida, “Parallel Firing of Produc tion System Programs,” IEEE Trans. KDE, Vol. 3, No.l, pp. 11-17, 1991. ↩ ↩2 ↩3
-
[Ishida and Korf, 1991] T. Ishida and R. E. Korf, “Moving Target Search,” IJCAI-91, pp. 204-210, 1991. ↩ ↩2
-
[Ishida et al., 1991] T. Ishida, Y. Sasaki and Y. Fukuhara, “Use of Procedural Programming Lan guages for Controlling Production Systems,” CAIA 91, pp. 71-75, 1991. ↩ ↩2
-
[Ishida, 1992a] T. Ishida, “Moving Target Search with Intelligence,” AAAI-9~, pp. 525-532, 1992. ↩ ↩2
-
[Ishida, 1992b] T. Ishida, “A Transaction Model for Multiagent Production Systems,” CAIA-9~, pp. 288-294, 1992. ↩ ↩2 ↩3
-
[Ishida et al., 1992] T. Ishida, L. Gasser and M. Yokoo, “Organization Self-Design of Distributed Production Systems,” IEEE Trans. KDE, Vol. 4, No. 2, pp. 123-134, 1992. ↩ ↩2
-
[Ishida et al., 1995] T. Ishida, Y. Sasaki, K. Nakata and Y. Fukuhara, “An Meta-Level Control Architec ture for Production Systems,” IEEE Trans. KDE, Vol. 7, No.l, pp. 44-52, 1995. ↩ ↩2
-
[Korf, 1990] It. E. Korf, “Real-Time Heuristic Search,” Artificial Intelligence, Vol. 42, No. 2-3, pp. 189-211. 1990. ↩ ↩2
-
[Kuwabara et al., 1995] K. Kuwahara, T. Ishida and N. Osato, “AgenTalk: Coordination Protocol De scription for Muitiagent Systems,” ICMAS-95 (The full version is available as Technical Report oflEICE, AI94-56), 1995. ↩ ↩2 ↩3
-
[Kuwabara, 1995] K. Kuwabara, AgenTalk 1.0 Refer ence Manual, 1995. ↩ ↩2
-
[Smith, 1980] R. G. Smith, “The Contract Net Pro tocol: High-Level Communication and Control in a Distributed Problem Solver,” IEEE Trans. Comput ers, Vol. 29, No. 12, pp. 1104-1113, 1980. ↩ ↩2
-
[Soloway et al., 1987] E. Soloway, J. Bachaut and K. Jensen, “Assessing the Maintainability of XCON-in RIME: Coping with the Problem of a VERY Large Rule-base,” AAAI-87, pp. 824-829, 1987. ↩ ↩2
-
[Watkins, 1989] C. J. C. H. Watkins, Learning from Delayed Rewards, PhD thesis, Cambridge, 1989. ↩ ↩2
-
[Yokoo et ai., 1992] M. Yokoo, E. H. Durfee, T. Ishida and K. Kuwabara, “Distributed Constraint Satisfac tion for Formalizing Distributed Problem Solving,” ICDCS-92, pp. 614-621, 1992. ↩ ↩2