") Driessen, Vincent
Driessen, Vincent
https://nvie.com/ Thoughts and writings by Vincent Driessen.
- Un modelo de Git-Branching con éxito
- 1. ¿Por qué Git?
- 2. Descentralizado versus Centralizado
- 3. Las ramas principales
- 4. Ramas auxiliares
- Resumen

Reflexión sobre el método para aplicar Git-Branching con éxito
License: CC-BYVincent Driessen (2020)
Un modelo de Git-Branching con éxito
Original en: https://nvie.com/posts/a-successful-git-branching-model/
Reflexión: notas de (5 de marzo, 2020)
Este modelo fue concebido en 2010, ahora hace más de 10 años, y no mucho después de que Git se creara. En esos 10 años, git-flow (el modelo de ramificación presentado en este artículo) se ha vuelto muy popular en muchos equipos de software, hasta el punto que las personas han comenzado a tratarlo como una especie de estándar, pero desafortunadamente también como un dogma o una panacea.
Durante esos 10 años, Git en sí ha conquistado el mundo, y el tipo de software más popular que se está desarrollando con Git se está desplazando más hacia las aplicaciones Web, al menos en mi ámbito de conocimientos. Por lo general, las aplicaciones Web se entregan de forma continua, nunca se revierten a versiones previas, y tampoco es necesario generar varias versiones del software que se ejecutan en el servidor Web.
Esta no es la clase de software que tenía en mente cuando escribí la entrada del blog hace 10 años. Si su equipo realiza una entrega continua de software, sugeriría adoptar un flujo de trabajo mucho más simple (como el flujo de GitHub) en lugar de intentar calzar git-flow en su equipo.
Sin embargo, si está creando software que está explícitamente versionado, o si necesita mantener varias versiones de su software, entonces git-flow aún puede ser tan bueno para su equipo como lo ha sido para las muchas personas durante los últimos 10 años. En ese caso, sigue leyendo.
Para concluir, recuerda siempre que las panaceas no existen. Considere su propio contexto. No entres en una espiral de odio el modelo. Y, decide por ti mismo.
En este post presento el modelo de desarrollo que introduje para algunos de mis proyectos (tanto laborales como privados) hace aproximadamente un año, y que ha resultado ser muy exitoso. Tenía la intención de escribir sobre eso desde hace un tiempo, pero nunca había encontrado el tiempo para hacerlo a fondo, hasta ahora. No hablaré sobre ninguno de los detalles de los proyectos, simplemente sobre la estrategia de ramificación y la gestión de versiones.
1. ¿Por qué Git?
Para una discusión detallada sobre pros y contras de Git, frente a los sistemas centralizados de control de código fuente, puede consultar la Web. Hay muchas guerras de que aún siguen en llamas por ahí. Como desarrollador, prefiero Git por encima de todas las demás herramientas actuales. Git realmente cambió la forma en que los desarrolladores piensan sobre la fusión y la ramificación. Del mundo clásico de CVS/Subversion del que vengo, fusionar/ramificar siempre se ha considerado un poco aterrador (“¡cuidado con los conflictos de fusión, ¡Que te muerden! y además, es algo que solo haces muy de vez en cuando.
Pero con Git, estas acciones son extremadamente baratas y simples, y se consideran realmente una de las partes centrales de su flujo de trabajo diario. Por ejemplo, en los libros de CVS/Subversion, la bifurcación y la fusión se tratan por primera vez en los capítulos posteriores (para usuarios avanzados), mientras que en todos los libros de Git ya se trata en el capítulo 3 (aspectos básicos).
Como consecuencia de su simplicidad y naturaleza repetitiva, las ramificaciones y fusiones ya no son algo a lo que temer. Se supone que las herramientas de control de versiones ayudan en la bifurcación/fusión más que cualquier otra cosa.
Ya basta de herramientas, pasemos al modelo de desarrollo. El modelo que voy a presentar aquí no es más que un conjunto de procedimientos que cada miembro del equipo debe seguir para llegar a un proceso de desarrollo de software administrado.
2. Descentralizado versus Centralizado
La configuración del repositorio que usamos y que funciona bien con este modelo de ramificación, es la que tiene un repositorio central de “verdad”. Tenga en cuenta que este repositorio solo se considera central (dado que Git es un DVCS, no existe un repositorio central a nivel técnico). Nos referiremos a este repositorio como origin, ya que este nombre es familiar para todos los usuarios de Git.
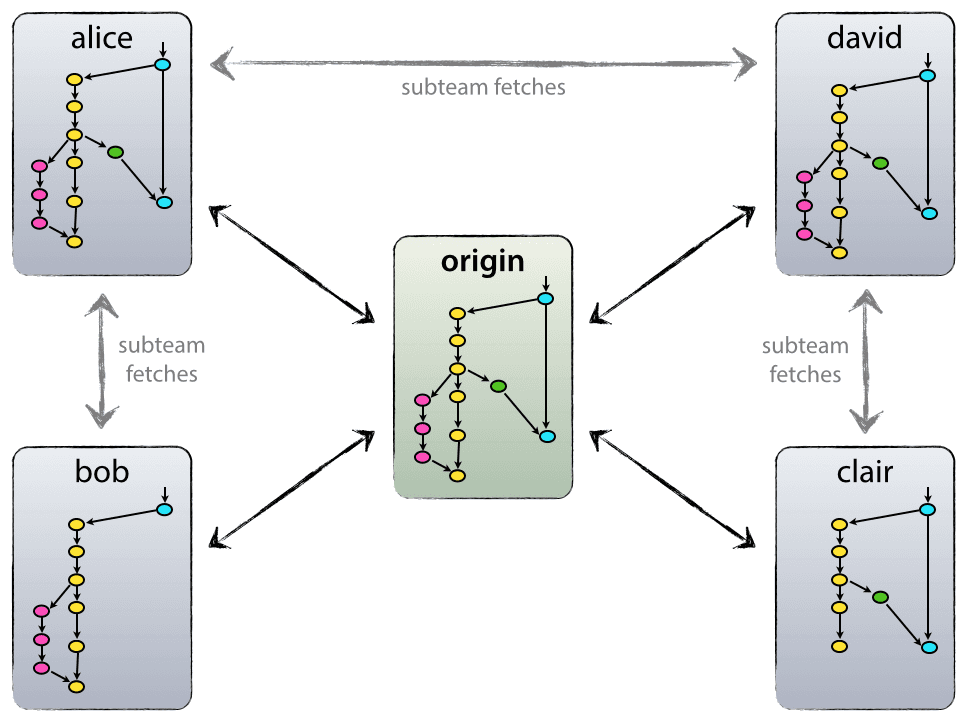
Cada desarrollador tira y empuja al origin. Pero además de las relaciones push-pull centralizadas, cada desarrollador también puede obtener cambios de otros pares para formar subequipos. Por ejemplo, esto podría ser útil para trabajar junto con dos o más desarrolladores en una gran función nueva, antes de llevar el trabajo en curso a su origin prematuramente. En la figura anterior, hay subequipos de Alice y Bob, Alice y David y Clair y David.
Técnicamente, esto no significa nada más que Alice ha definido un control remoto de Git, llamado bob, que apunta al repositorio de Bob, y viceversa.
3. Las ramas principales
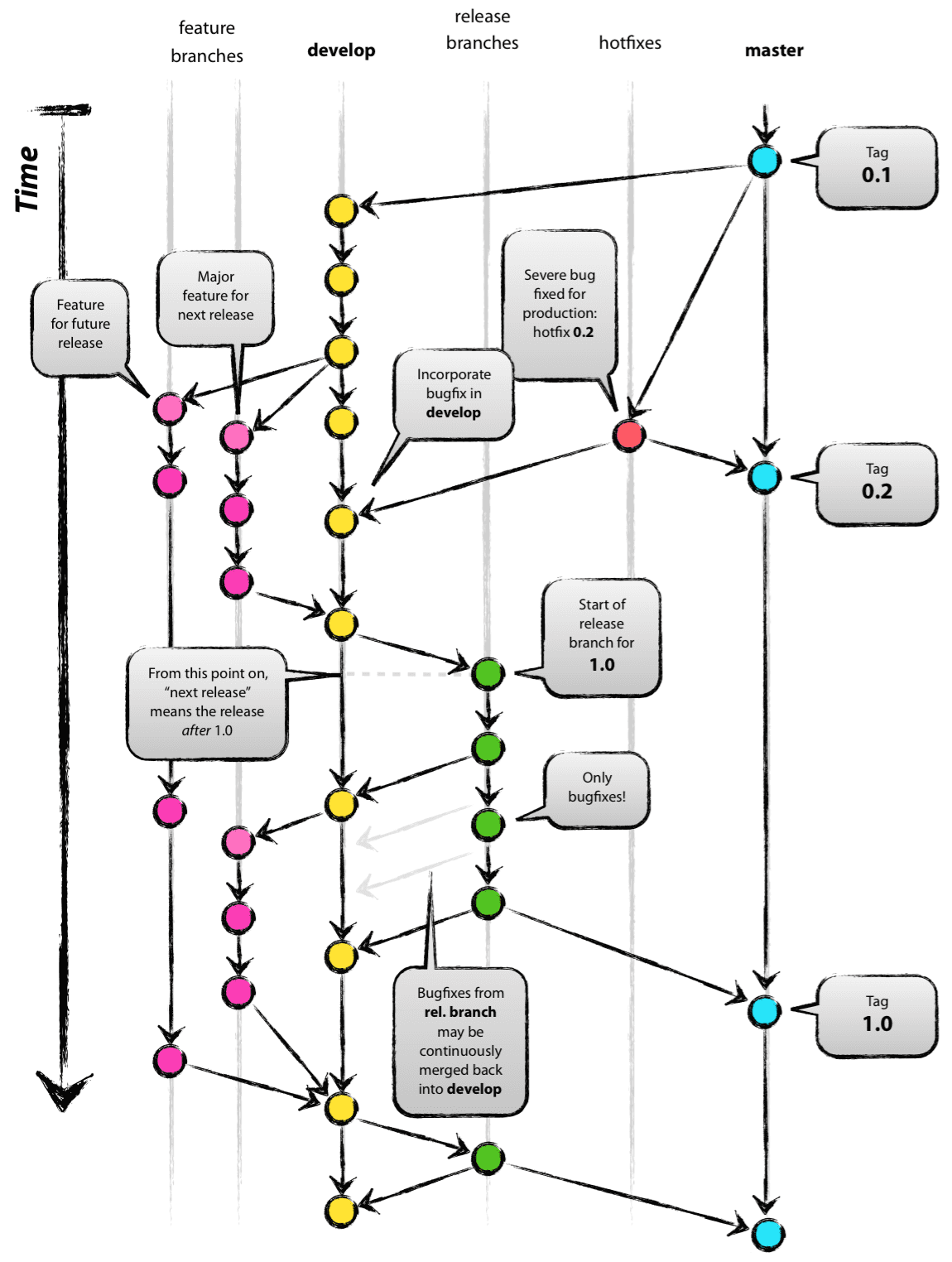
En esencia, el modelo de desarrollo está muy inspirado en los modelos existentes. El repositorio central contiene dos ramas principales con una vida útil infinita:
master
develop
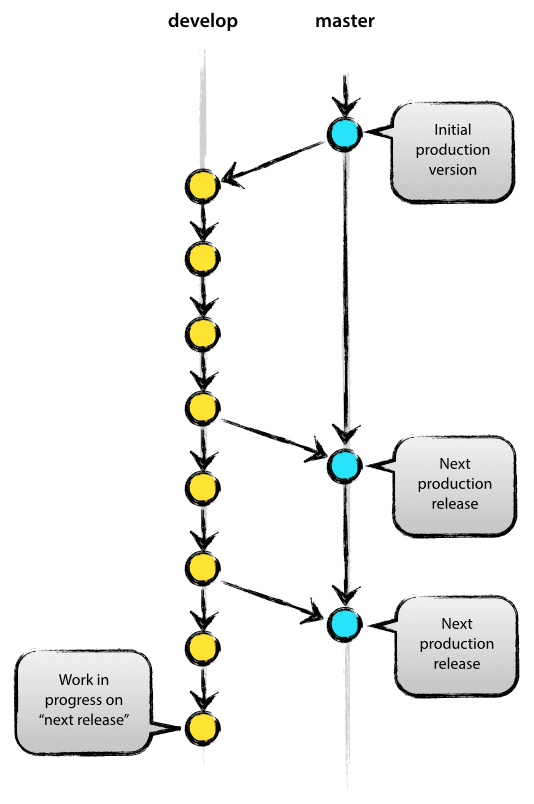
La rama master en la localización origin debería ser familiar para todos los usuarios de Git. Paralelamente a la rama master, existe otra rama principal llamada develop.
Consideramos que origin/master es la rama principal donde el código fuente con el identificador HEAD siempre reflejará el estado de código ‘listo’ para pasar a producción.
Consideramos que origin/develop es la rama principal donde el código fuente con identificador HEAD siempre reflejará el estado con los últimos cambios de desarrollo entregados para la próxima versión. Algunos llamarían a esto la “rama de integración”. Aquí es donde se construyen, mediante compilaciones automáticas y nocturna, las veriones del software en estado de desarrollo.
Cuando el código fuente en la rama develop (o de desarrollo) alcanza un punto estable y está listo para publicarse, todos los cambios deben fusionarse de nuevo en la rama master de alguna manera y luego etiquetarse con un número de identificación de la versión para su liberación. El cómo se hace esto con todo detalle, se discutirá más adelante.
Por lo tanto, cada vez que los cambios se vuelven a fusionar en la rama master, se trata por definición de una nueva versión de producción. Tendemos a ser muy estrictos en esto, por lo que, en teoría, podríamos usar un script de tipo Git Hook, para compilar e implementar automáticamente nuestro software en nuestros servidores de producción cada vez que haya una confirmación en la rama master.
4. Ramas auxiliares
Junto a las ramas principales master y develop, nuestro modelo de desarrollo utiliza una variedad de ramas auxiliares de apoyo que ayunda a llevar a cabo los desarrollos en paralelo entre los miembros del equipo; también facilitan el seguimiento de las funciones, prepararse para los lanzamientos de producción y para ayudar a solucionar rápidamente los problemas de producción en vivo y sobre la marcha. A diferencia de las ramas principales, estas ramas siempre tienen un tiempo de vida limitado, ya que eventualmente pueden ser eliminadas.
Los diferentes tipos de ramas que podemos utilizar son:
Feature branches (Ramas de nuevas funcionalidades)
Release branches (Ramas de versiones a liberar)
Hotfix branches (Ramas de parches a aplicar)
Cada una de estas ramas tiene un propósito específico y está sujeta a reglas estrictas en cuanto a qué ramas pueden ser su rama de partida o generadora y qué ramas deben ser sus objetivos de fusión. Vamos a caminar a través de ellos en un minuto.
De ninguna manera estas ramas son “especiales” desde una perspectiva técnica. Los tipos de rama están categorizados por cómo las utilizamos. Son, por tanto, las simples y viejas ramas de Git.
4.1. (Feature branches): ramas donde desarrollar nuevas funcionalidades
Deben ser creadas desde la rama:
develop
Deben fusionarse de nuevo en:
develop
Covención de nomenclatura de estas ramas:
cualquier nombre excepto:
master, develop, release-*, or hotfix-*
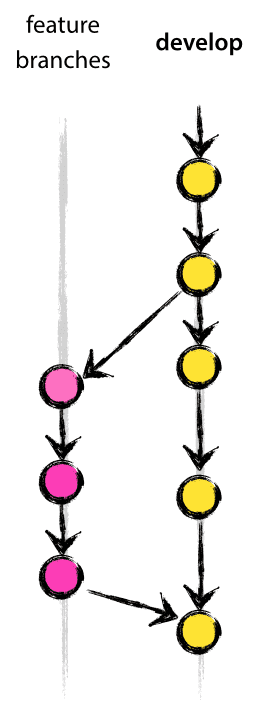
Las ramas dedicadas a desarrollar nuevas funcionalidades (Feature Branches), llamadas también ramas temáticas, se utilizan para desarrollar nuevas funciones para la próxima versión o para un futuro lejano.
Al iniciar el desarrollo de una función, es posible que en ese momento se desconozca la versión de destino en la que se incorporará esta función. La esencia de una rama de función es que existe mientras la función esté en desarrollo, pero eventualmente se fusionará nuevamente en desarrollo (para agregar definitivamente la nueva función a la próxima versión) o se descartará (en caso de que resulte un experimento decepcionante).
Las Feature branches normalmente existen sólo en repositorios de desarrolladores, y no se suelen subir nunca al origin.
4.1.1. Creación de una Feature branch
Al comenzar a trabajar en una nueva funcionalidad, bifúrquese la rama de desarrollo develop mediante:
$ git checkout -b myfeature develop
Crear y moverse a la rama "myfeature" a partir de develop
4.1.2. Incorporación de una funcionalidad terminada en develop
Las funcionalidades terminadas se pueden fusionar en la rama develop para agregarlas definitivamente a la próxima versión:
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff myfeature
Updating ea1b82a..05e9557
(Summary of changes)
$ git branch -d myfeature
Deleted branch myfeature (was 05e9557).
$ git push origin develop
El indicador --no-ff hace que la combinación cree siempre un nuevo objeto de confirmación tipo commit, incluso si la combinación se puede realizar con un avance rápido. Esto evita perder información sobre la existencia histórica de una rama de tipo Feature Branch y agrupa todas las confirmaciones que agregaron la función. Comparar en la imagen el resultado con y sin --no-ff:
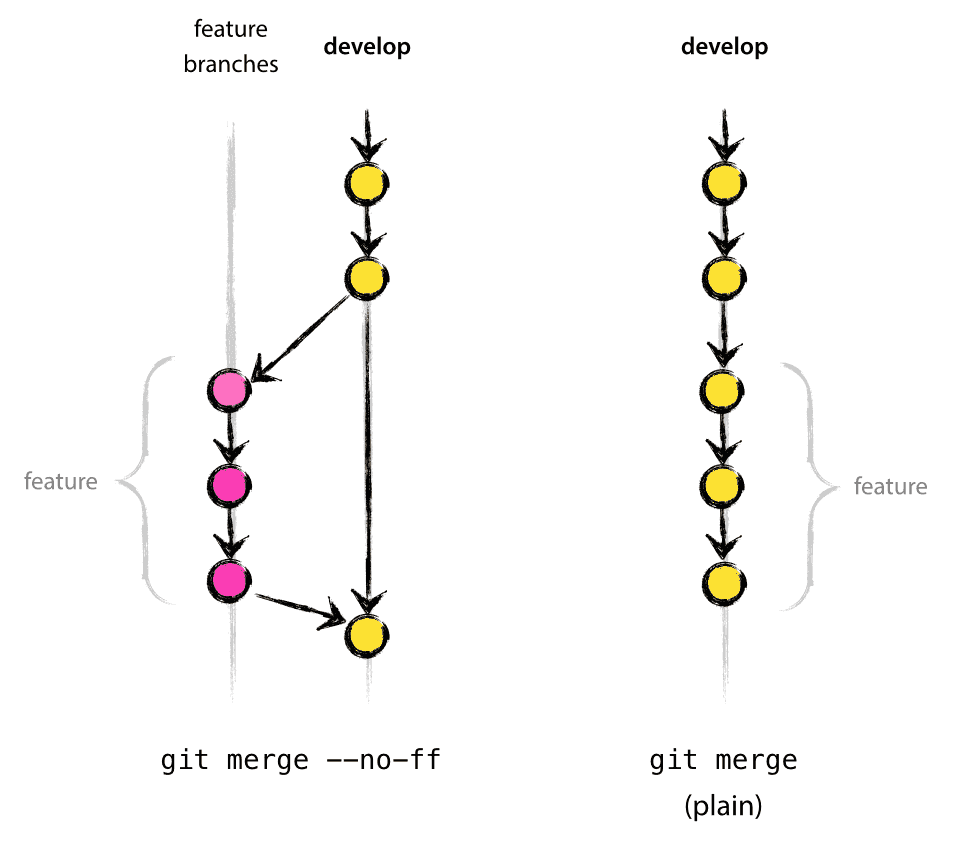
En el segundo caso en la imagen, es imposible ver en el historial de Git cuál de los objetos de commit progresivos es el que ha implementado una característica concreta; tendría que leer manualmente todos los mensajes del registro. Revertir una funcionalidad completa (es decir, un grupo de commits) es un verdadero dolor de cabeza en la segunda situación, mientras que, si se usa el indicador --no-ff en la fusión, esta operación de detección de qué commit representa la funcinalidad, se puede realizar de manera directa su localicación.
Sí, creará algunos objetos de confirmación más (vacíos), pero la ganancia es mucho mayor que el coste.
4.2. (Release Branches): ramas de versión
Deben ser creadas desde la rama:
develop
Deben fusionarse de nuevo en:
develop, y luego en: master
Covención de nomenclatura de estas ramas:
release-*
Estas ramas están destinadas a contener el código de una versión de producción. Permiten establecer el número y recibir las últimas modificaciones cruzadas, normalmente por el tipo de arquitectura al que vaya dirigida esa versión. Además, permiten corregir errores menores y preparar metadatos para un lanzamiento (número de versión, fechas de compilación, etc.). Al hacer todo este trabajo en una rama de lanzamiento, la rama develop queda liberada y puede ser autorizada a recibir nuevas funcionalidades para liberar en próximos lanzamientos.
El momento clave para crear una rama de tipo versión a partir de la rama develop es cuando el desarrollo (casi) refleja el estado deseado para la nueva versión. Al menos cuenta con todas las funcionalidades que están destinadas a la versión por construir y dichas ramas deben fusionarse en develop en ese momento. Es posible que no todas las funciones destinadas a versiones futuras, pues esas deben esperar hasta después de que se genere la rama de versión.
Es exactamente al comienzo de una rama de release o versión, cuando se le asigna un número de versión al próximo lanzamiento, no antes. Hasta ese momento, la rama develop reflejaba cambios para la “próxima versión”, pero no está claro si esa “próxima versión” eventualmente se convertirá en 0.3 o 1.0, hasta que se construya la rama de release. Esa decisión se toma al comienzo de la rama de release y se lleva a cabo según las reglas del proyecto sobre el aumento del número de versión.
4.2.1. Creación de ramas de versión (Release Branch)
Las ramas de lanzamiento se crean a partir de la rama develop. Por ejemplo, digamos que la versión 1.1.5 es el lanzamiento de producción actual y tenemos un gran lanzamiento por venir. El estado de desarrollo está listo para la “próxima versión” y hemos decidido que se convertirá en la versión 1.2 (en lugar de 1.1.6 o 2.0). Así que nos bifurcamos y le damos a la rama de versión un nombre que refleje el nuevo número de versión:
$ git checkout -b release-1.2 develop
Switched to a new branch "release-1.2"
$ ./bump-version.sh 1.2
Files modified successfully, version bumped to 1.2.
$ git commit -a -m "Bumped version number to 1.2"
[release-1.2 74d9424] Bumped version number to 1.2
1 files changed, 1 insertions(+), 1 deletions(-)
Después de crear una nueva rama y cambiar a ella, aumentamos el número de versión. Aquí, bump-version.sh es un script de shell ficticio que cambia algunos archivos en la copia de trabajo para reflejar la nueva versión. (Por supuesto, esto puede ser un cambio manual; el punto es que algunos archivos cambian). Luego, se hace un commit con el número de versión aumentado.
Esta nueva rama puede existir por un tiempo, hasta que el lanzamiento se implemente definitivamente. Durante ese tiempo, se pueden aplicar correcciones de errores en esta rama de versión (en lugar de en la rama de desarrollo).
Está terminantemente prohibido agregar grandes características nuevas aquí. Deben fusionarse en develop y, por lo tanto, esperar el próximo gran lanzamiento.
4.2.2. Finalización de una rama de versión
Tomemos por ejemplo como nombre release-1.2 para la rama de versión.
Cuando el estado de la rama de versión release-1.2 está listo para convertirse en un lanzamiento real, se deben llevar a cabo algunas acciones. Primero, la rama de versión se fusiona con la rama master (ya que cada confirmación en el maestro es un nuevo lanzamiento por definición, recuerde). A continuación, ese commit en el master debe etiquetarse para una fácil referencia futura a esta versión histórica. Finalmente, los cambios realizados en la rama de versión release-1.2 deben fusionarse nuevamente en la rama develop, de modo que los lanzamientos futuros también contengan estas correcciones de errores.
Los primeros dos pasos en consola de Git son:
$ git checkout master
Switched to branch 'master'
$ git merge --no-ff release-1.2
Merge made by recursive.
(Summary of changes)
$ git tag -a 1.2
El lanzamiento ya está hecho y etiquetado para futuras referencias.
Destacar: Es posible que desee usar los parámetros
-so-u <key>para firmar su etiqueta criptográficamente.
Sin embargo, para mantener los cambios realizados en la rama de lanzamiento release-1.2, debemos fusionarlos nuevamente en la rama develop. En Git:
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff release-1.2
Merge made by recursive.
(Summary of changes)
Este paso podría llevar a una conflicto de fusión (probablemente incluso aún más, ya que hemos cambiado el número de versión en algunos archivos). Si es así, arréglelo y haga commit.
Ahora hemos terminado y la rama de versión ya puede eliminarse, pues no la necesitamos:
$ git branch -d release-1.2
Deleted branch release-1.2 (was ff452fe).
4.3. (Hotfix branches): ramas de correcciones
Deben ser creadas desde la rama:
master
Deben fusionarse de nuevo en:
develop, y : master
Covención de nomenclatura de estas ramas:
hotfix-*
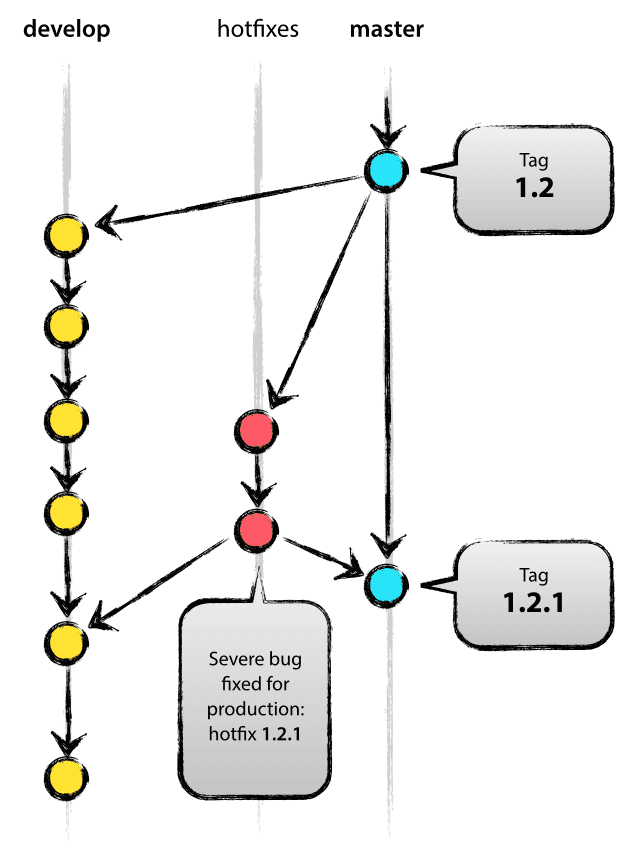
Las ramas de correcciones son muy parecidas a las ramas de versión en el sentido de que también están destinadas a prepararse para una nueva versión de producción, aunque no planificada. Surgen de la necesidad de actuar inmediatamente ante un estado no deseado de una versión de producción en servicio. Cuando un error crítico en una versión de producción debe resolverse de inmediato, una rama de correcciones puede derivarse de la etiqueta correspondiente en la rama master que marca la versión de producción.
La esencia es que el trabajo de los miembros del equipo (en la rama develop) puede continuar, mientras otra persona prepara una solución de producción rápida.
4.3.1. Creación de la rama de correcciones
Las ramas de revisión se crean a partir de la rama maestra. Por ejemplo, digamos que la versión 1.2 es la versión de producción actual que se ejecuta en vivo y causa problemas debido a un error grave. Pero los cambios en desarrollo aún son inestables. Luego, podemos ramificar una rama de revisión y comenzar a solucionar el problema:
$ git checkout -b hotfix-1.2.1 master
Switched to a new branch "hotfix-1.2.1"
$ ./bump-version.sh 1.2.1
Files modified successfully, version bumped to 1.2.1.
$ git commit -a -m "Bumped version number to 1.2.1"
[hotfix-1.2.1 41e61bb] Bumped version number to 1.2.1
1 files changed, 1 insertions(+), 1 deletions(-)
Don’t forget to bump the version number after branching off!
Then, fix the bug and commit the fix in one or more separate commits.
¡No olvide cambiar el número de versión después de bifurcarse!
Luego, solucione el error y confirme con un commit la corrección en uno o más commits separados.
$ git commit -m "Fixed severe production problem"
[hotfix-1.2.1 abbe5d6] Fixed severe production problem
5 files changed, 32 insertions(+), 17 deletions(-)
4.3.2. Finalización de una rama de correción (Hotfix branch)
Cuando finalice, la corrección de errores debe fusionarse nuevamente con la rama master, pero también debe fusionarse nuevamente con la rama develop, para salvaguardar que la corrección de errores también se incluya en la próxima versión. Esto es completamente similar a cómo se terminan las ramas de versión.
Primero, actualice el master y etiquete la versión.
$ git checkout master
Switched to branch 'master'
$ git merge --no-ff hotfix-1.2.1
Merge made by recursive.
(Summary of changes)
$ git tag -a 1.2.1
Destacar: Es posible que desee usar los parámetros
-so-u <key>para firmar su etiqueta criptográficamente.
A continuación, incluya también la corrección de errores en la rama develop:
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff hotfix-1.2.1
Merge made by recursive.
(Summary of changes)
La única excepción a la regla aquí es que, cuando existe actualmente una rama de versión, los cambios de la corrección deben fusionarse en esa rama de versión, en lugar de en la rama de develop.
La fusión posterior de la corrección de errores en la rama de versión eventualmente dará como resultado que la corrección de errores se fusione también en desarrollo (rama develop), cuando finalice la rama de versión.
(Si el trabajo en la rama develop requiere inmediatamente esta corrección de errores y no puede esperar a que finalice la rama de versión, también puede fusionar de forma segura la rama de correcciones en la rama develop ahora).
Finalmente, elimine la rama temporal:
$ git branch -d hotfix-1.2.1
Deleted branch hotfix-1.2.1 (was abbe5d6).
Resumen
Si bien no hay nada nuevo realmente impactante en este modelo de ramificación, la figura del “panorama general” con la que comenzó esta publicación ha resultado ser tremendamente útil en nuestros proyectos. Forma un modelo mental elegante que es fácil de comprender y permite a los miembros del equipo desarrollar una comprensión compartida de los procesos de ramificación y versionado del código.